Two prototypes, one engine.
Same analysis, completely different product.
We started by building the analytical engine as its own opinionated product — a dark, AI-forward scorecard that shows what a modern credit workstation could look like if it were designed from scratch around AI-generated reasoning. Then we took that same engine and re-skinned it as a publication-grade credit report, slotted into an existing publisher's site, reader base, and editorial voice.
A standalone AI credit workstation.
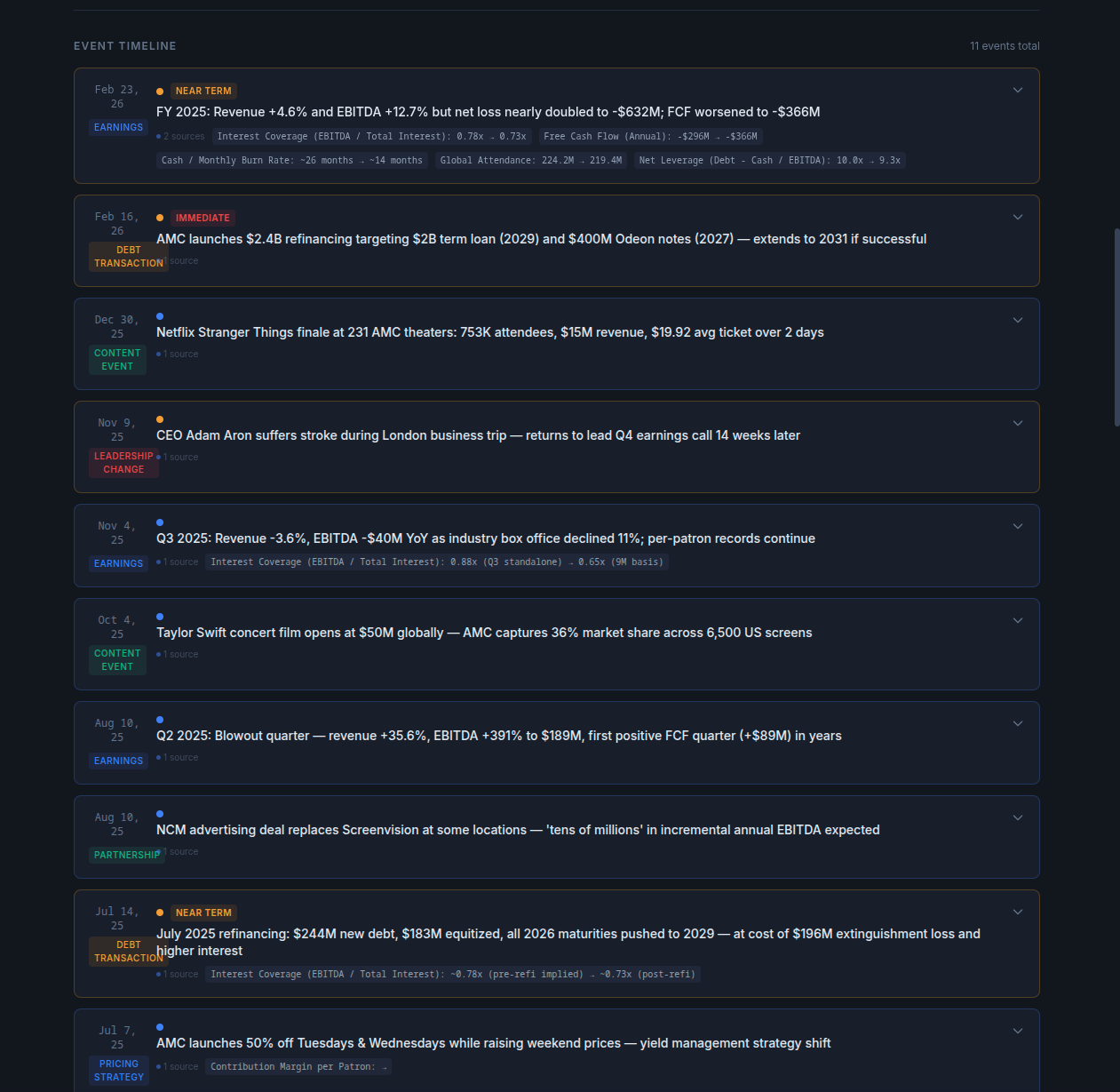
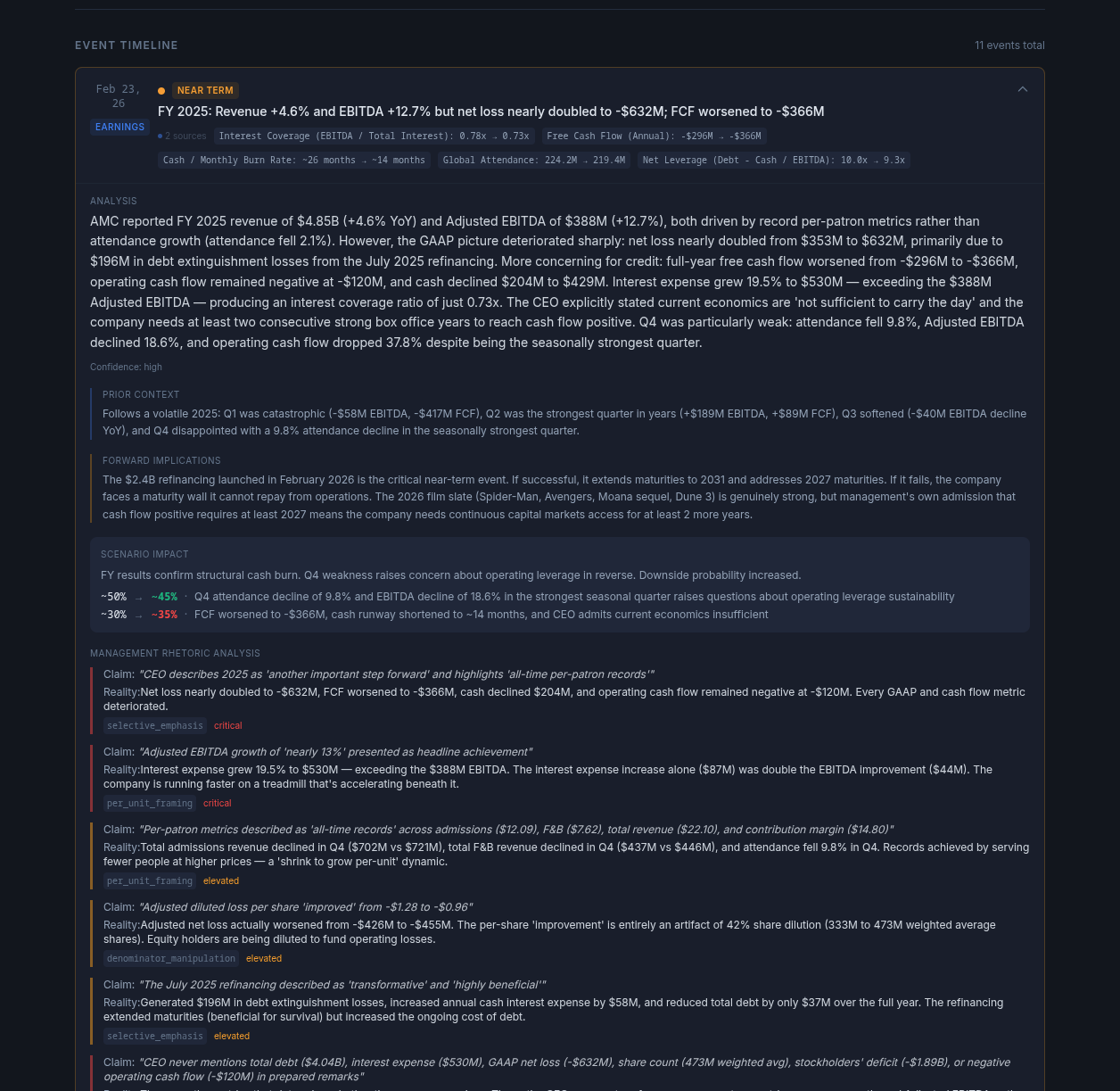
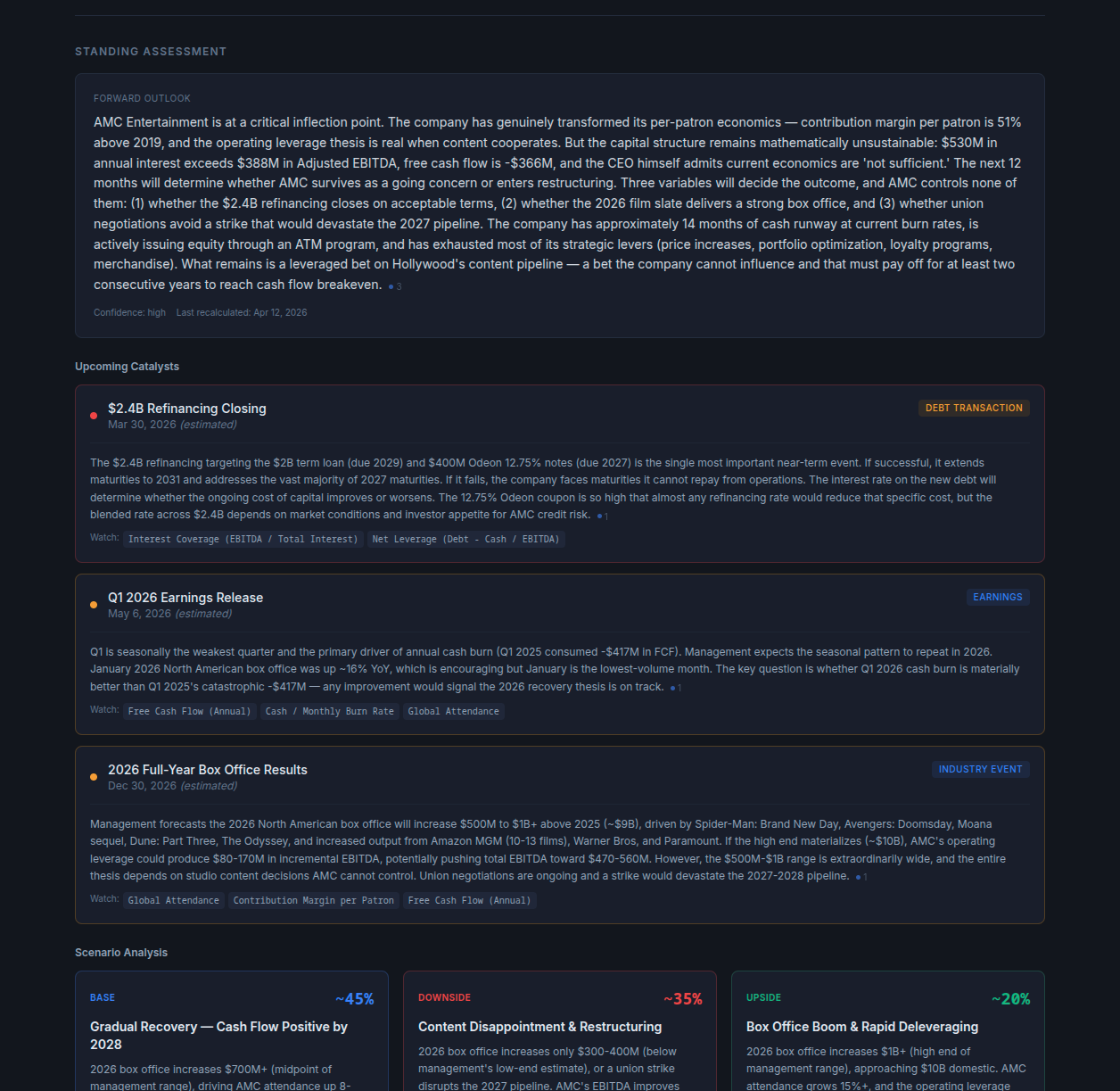
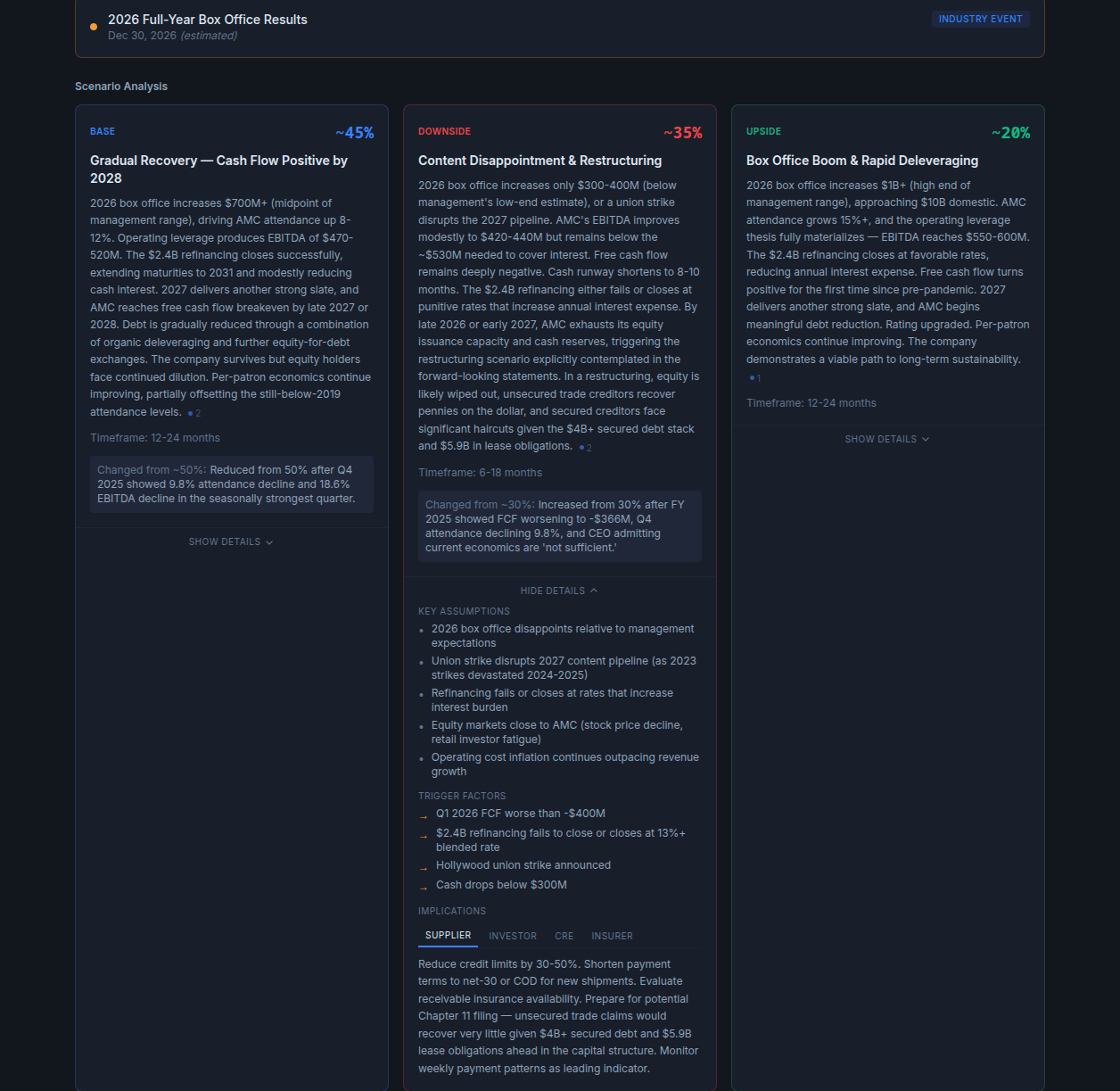
Dark, dense, designed around the analytical engine itself. Every surface pushes the AI reasoning forward — flash alerts, scenario trees, timeline events, management-rhetoric deconstruction. Built to prove the depth and defensibility of the analysis.
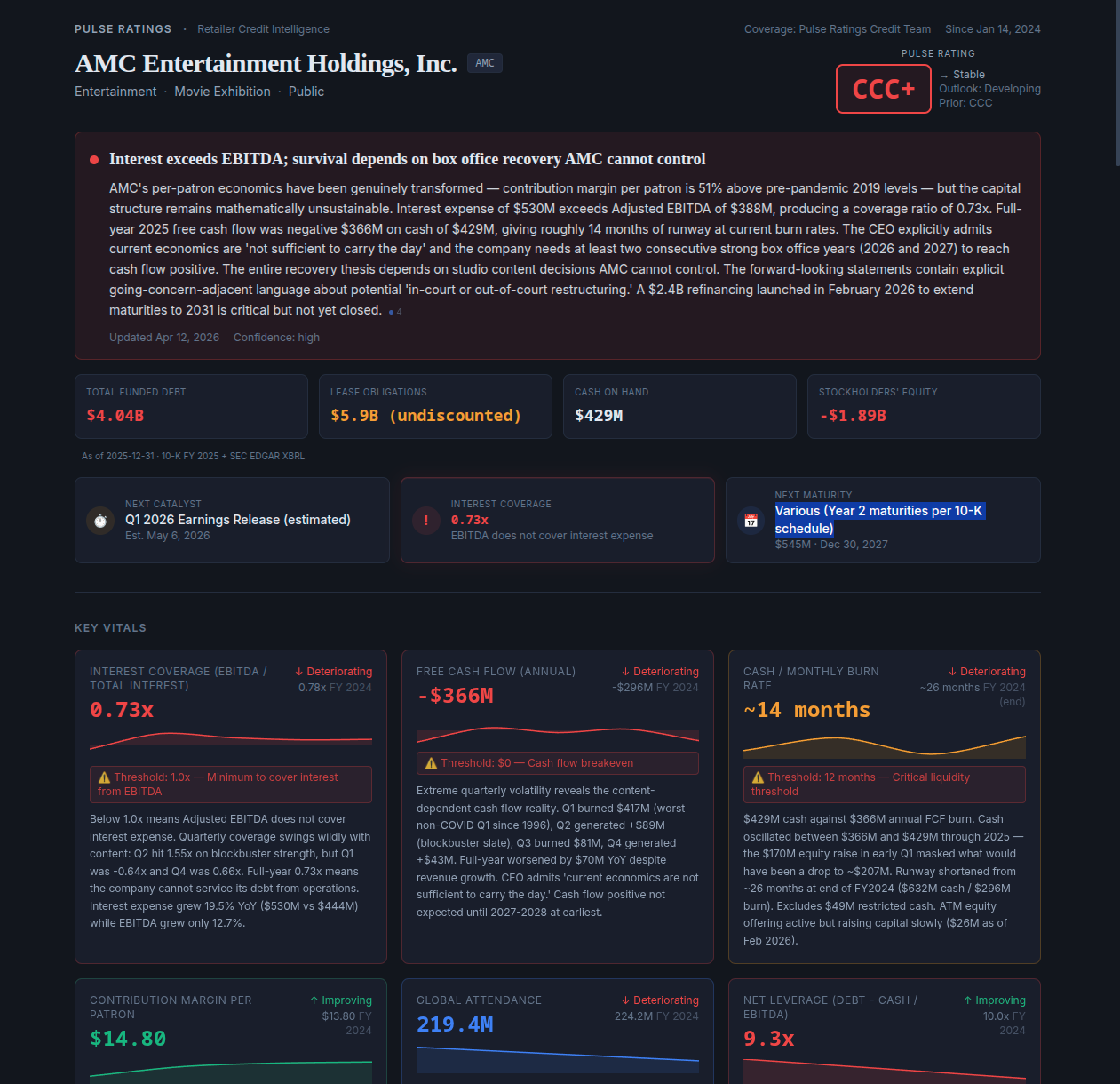
The same engine, wearing the client's brand.
Light, editorial, dropped inside the client's existing research publication — complete with navigation, tear sheet, rating history, related coverage, and sidebar alerts. The analytical engine is identical. The product around it is something subscribers would recognize as theirs.
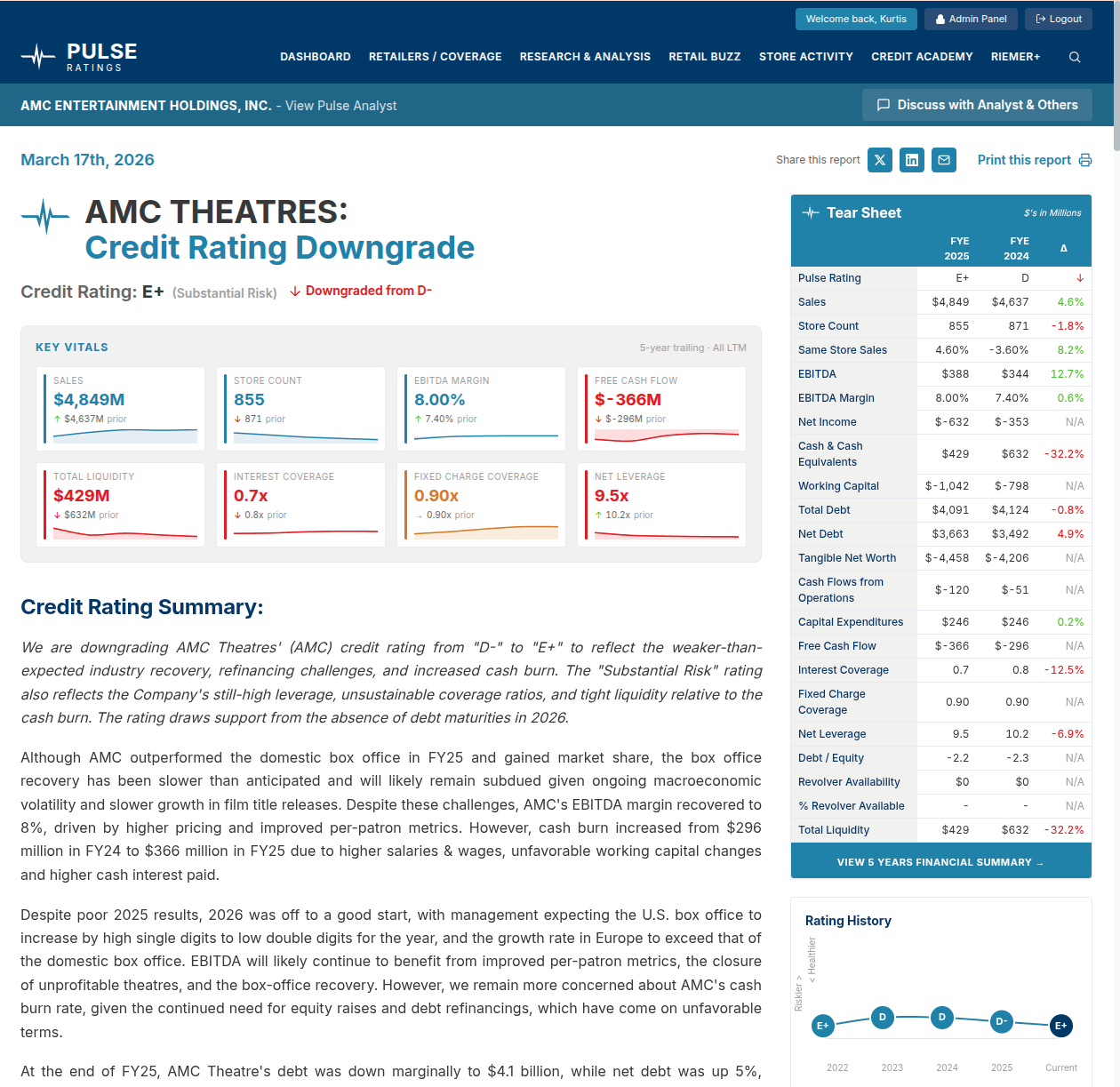
The first prototype is the pitch: this is what the engine can do. The second prototype is the product: this is what it looks like in your business. Splitting those two conversations let the client see both the ambition and the path to shipping — without collapsing one into the other.